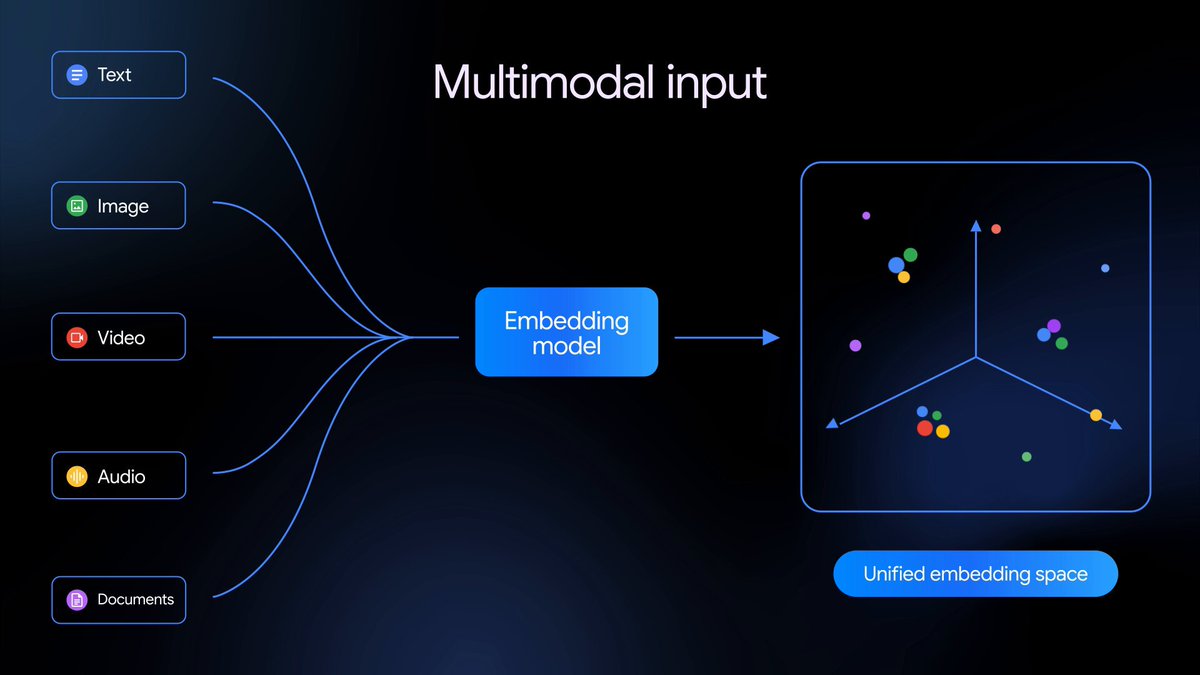
Gemini Embedding 2 ist unser erstes nativ multimodales Einbettungsmodell, das Text, Bilder, Videos, Audio und Dokumente in einen einzigen Einbettungsraum abbildet und so multimodale Suche und Klassifizierung über verschiedene Medientypen hinweg ermöglicht – und es ist ab sofort in der öffentlichen Vorschau verfügbar.
Heute veröffentlichen wir Gemini Embedding 2, unser erstes vollständig multimodales Einbettungsmodell, das auf der Gemini-Architektur basiert, in der Public Preview über die Gemini API und Vertex AI.
Aufbauend auf unserem bisherigen rein textbasierten Fundament bildet Gemini Embedding 2 Text, Bilder, Videos, Audio und Dokumente in einen einzigen, einheitlichen Einbettungsraum ab und erfasst semantische Absichten in über 100 Sprachen. Dies vereinfacht komplexe Pipelines und verbessert eine Vielzahl von multimodalen Aufgaben – von Retrieval-Augmented Generation (RAG) und semantischer Suche bis hin zu Sentimentanalyse und Datenclustering.
Neue Modalitäten und flexible Ausgabedimensionen
Das Modell basiert auf Gemini und nutzt dessen erstklassige multimodale Verständnisfähigkeiten, um hochwertige Einbettungen zu erstellen für:
- Text: Unterstützt einen umfangreichen Kontext von bis zu 8192 Eingabe-Token
- Bilder: Kann bis zu 6 Bilder pro Anfrage verarbeiten, unterstützt PNG- und JPEG-Formate
- Videos: Unterstützt bis zu 120 Sekunden Videoeingabe in MP4- und MOV-Formaten
- Audio: Nimmt Audiodaten nativ auf und bettet sie ein, ohne dass eine zwischengeschaltete Texttranskription erforderlich ist
- Dokumente: Bettet PDFs mit bis zu 6 Seiten direkt ein
Über die Verarbeitung einer Modalität nach der anderen hinaus versteht dieses Modell nativ verschachtelte Eingaben, sodass Sie mehrere Modalitäten (z. B. Bild + Text) in einer einzigen Anfrage übergeben können. Dadurch kann das Modell die komplexen, nuancierten Beziehungen zwischen verschiedenen Medientypen erfassen und ein genaueres Verständnis komplexer, realer Daten ermöglichen.
0:37
Wie unsere bisherigen Einbettungsmodelle integriert Gemini Embedding 2 Matryoshka Representation Learning (MRL), eine Technik, die Informationen durch dynamische Dimensionsreduzierung „verschachtelt". Dies ermöglicht flexible Ausgabedimensionen, die von den standardmäßigen 3072 skaliert werden können, sodass Entwickler Leistung und Speicherkosten ausbalancieren können. Wir empfehlen die Verwendung von 3072, 1536, 768 Dimensionen für höchste Qualität.
Modernste Leistung
Gemini Embedding 2 verbessert nicht nur ältere Modelle. Es setzt einen neuen Leistungsstandard für multimodale Tiefe, führt starke Sprachfähigkeiten ein und übertrifft führende Modelle bei Text-, Bild- und Videoaufgaben. Diese messbare Verbesserung und die einzigartige multimodale Abdeckung geben Entwicklern genau das, was sie für ihre vielfältigen Einbettungsanforderungen benötigen.

Tieferes Verständnis für Daten freischalten
Einbettungen sind die Technologie, die Erlebnisse in vielen Google-Produkten antreibt. Von RAG, wo Einbettungen eine entscheidende Rolle im Kontext-Engineering spielen können, bis hin zu groß angelegtem Datenmanagement und klassischer Suche/Analyse – einige unserer Early-Access-Partner nutzen Gemini Embedding 2 bereits, um hochwertige multimodale Anwendungen zu erschließen:
„Wir haben uns für Gemini-Einbettungen entschieden, um Juristen dabei zu helfen, während des Discovery-Prozesses in Rechtsstreitigkeiten kritische Informationen zu finden – eine hochtechnische Herausforderung in einem Umfeld mit hohen Einsätzen, bei der Gemini hervorragende Arbeit leistet. In unseren jüngsten Tests verbessert das multimodale Einbettungsmodell von Gemini Präzision und Recall bei Millionen von Datensätzen und ermöglicht gleichzeitig leistungsstarke neue Suchfunktionen für Bilder und Videos. Für Juristen eröffnen diese neuen Fähigkeiten völlig neue Wege, um Fallmaterialien auch in den größten Angelegenheiten schnell zu verstehen."
*
**Max Christoff
CTO
Everlaw**
„Gemini Embedding 2 ist die Grundlage für Sparkonomys Creator Economic Equality Engine. Seine native Multimodalität reduziert unsere Latenz um bis zu 70 %, indem LLM-Inferenz entfällt, und verdoppelt nahezu die semantischen Ähnlichkeitswerte für Text-Bild- und Text-Video-Paare – von 0,4 auf 0,8. Dies treibt unseren proprietären Creator Genome an, um Millionen von Minuten Video sowie Bilder und Text mit beispielloser Präzision zu indizieren – und ermöglicht unvoreingenommene Markenkooperationen und demokratisiert den wirtschaftlichen Erfolg für jeden Creator."
**Guneet Singh
Mitbegründer
Sparkonomy**
„Die API-Kontinuität ist hervorragend. Gemini Embedding 2 fügt sich mit minimalen Änderungen nahtlos in unseren bestehenden Workflow ein. Wir testen neue Wege, um textbasierte Gesprächserinnerungen zusammen mit Audio- und visuellen Einbettungen einzubetten, insbesondere Frage-Antwort-Paare des Assistenten, und sehen eine Steigerung des Top-1-Recall um 20 % für unsere persönliche Wellness-App."
**Ertuğrul Çavuşoğlu
Mitbegründer
Mindlid**
Jetzt mit dem Bauen beginnen
Erste Schritte mit dem Gemini Embedding 2-Modell über die Gemini API oder Vertex AI.
1from google import genai2from google.genai import types34# For Vertex AI:5# PROJECT_ID='<add_here>'6# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')78client = genai.Client()910with open("example.png", "rb") as f:11 image_bytes = f.read()1213with open("sample.mp3", "rb") as f:14 audio_bytes = f.read()1516# Embed text, image, and audio17result = client.models.embed_content(18 model="gemini-embedding-2-preview",19 contents=[20 "What is the meaning of life?",21 types.Part.from_bytes(22 data=image_bytes,23 mime_type="image/png",24 ),25 types.Part.from_bytes(26 data=audio_bytes,27 mime_type="audio/mpeg",28 ),29 ],30)3132print(result.embeddings)
Erfahren Sie, wie Sie das Modell in unseren interaktiven Colab-Notebooks für die Gemini API und Vertex AI verwenden. Sie können es auch über LangChain, LlamaIndex, Haystack, Weaviate, QDrant, ChromaDB und Vector Search nutzen.
Indem es den vielfältigen Daten um uns herum semantische Bedeutung verleiht, bietet Gemini Embedding 2 die wesentliche multimodale Grundlage für die nächste Ära fortschrittlicher KI-Erlebnisse. Wir sind gespannt, was Sie damit bauen werden.





