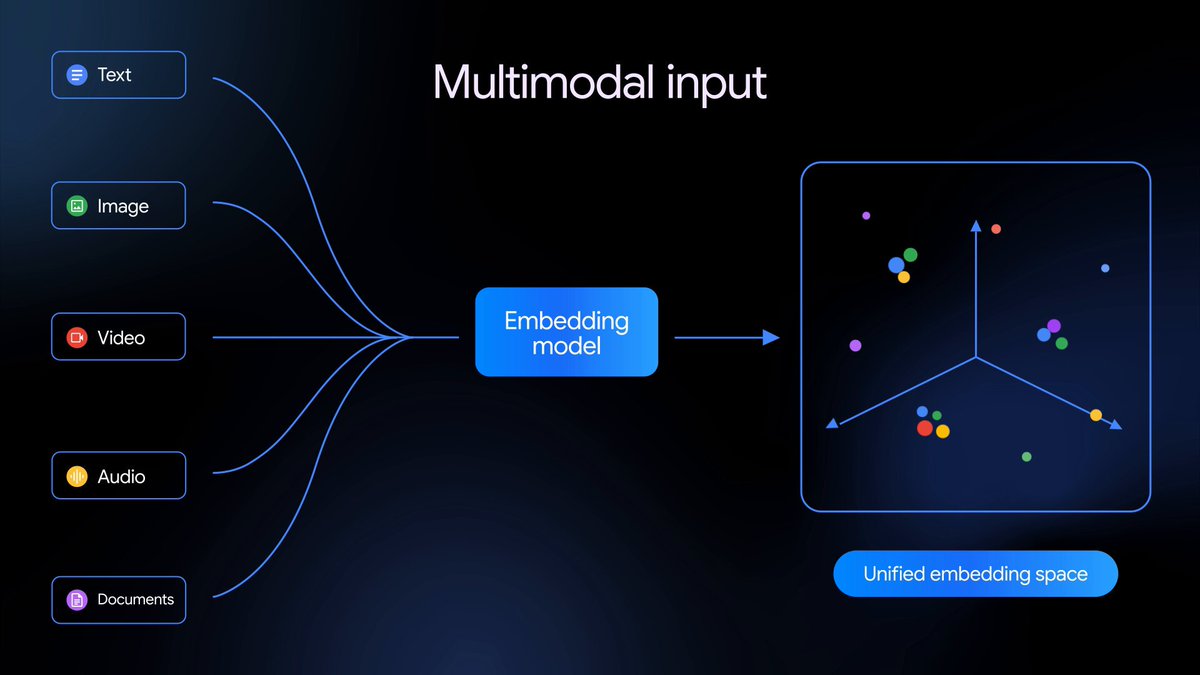
Gemini Embedding 2 es nuestro primer modelo de embeddings multimodal nativo que mapea texto, imágenes, video, audio y documentos en un único espacio de embeddings, permitiendo la recuperación y clasificación multimodal a través de diferentes tipos de medios — y ya está disponible en vista previa pública.
Hoy lanzamos Gemini Embedding 2, nuestro primer modelo de embeddings completamente multimodal construido sobre la arquitectura Gemini, en Vista Previa Pública a través de la API de Gemini y Vertex AI.
Ampliando nuestra base anterior solo de texto, Gemini Embedding 2 mapea texto, imágenes, videos, audio y documentos en un único espacio de embeddings unificado, y captura la intención semántica en más de 100 idiomas. Esto simplifica pipelines complejos y mejora una amplia variedad de tareas multimodales posteriores, desde Generación Aumentada por Recuperación (RAG) y búsqueda semántica hasta análisis de sentimientos y agrupación de datos.
Nuevas modalidades y dimensiones de salida flexibles
El modelo está basado en Gemini y aprovecha sus capacidades de comprensión multimodal de primer nivel para crear embeddings de alta calidad en:
- Texto: admite un contexto amplio de hasta 8192 tokens de entrada
- Imágenes: capaz de procesar hasta 6 imágenes por solicitud, compatible con formatos PNG y JPEG
- Videos: admite hasta 120 segundos de entrada de video en formatos MP4 y MOV
- Audio: ingiere e incrusta datos de audio de forma nativa sin necesidad de transcripciones de texto intermedias
- Documentos: incrusta directamente archivos PDF de hasta 6 páginas
Además de procesar una modalidad a la vez, este modelo entiende de forma nativa la entrada intercalada, por lo que puedes pasar múltiples modalidades de entrada (por ejemplo, imagen + texto) en una sola solicitud. Esto permite que el modelo capture las relaciones complejas y matizadas entre diferentes tipos de medios, desbloqueando una comprensión más precisa de datos complejos del mundo real.
0:37
Al igual que nuestros modelos de embeddings anteriores, Gemini Embedding 2 incorpora el Aprendizaje de Representación Matryoshka (MRL), una técnica que "anida" la información escalando dinámicamente las dimensiones. Esto permite dimensiones de salida flexibles que se reducen desde el valor predeterminado de 3072, para que los desarrolladores puedan equilibrar el rendimiento y los costos de almacenamiento. Recomendamos usar dimensiones de 3072, 1536, 768 para la máxima calidad.
Rendimiento de vanguardia
Gemini Embedding 2 no solo mejora los modelos anteriores. Establece un nuevo estándar de rendimiento para la profundidad multimodal, introduciendo sólidas capacidades de voz y superando a los modelos líderes en tareas de texto, imagen y video. Esta mejora medible y la cobertura multimodal única brindan a los desarrolladores exactamente lo que necesitan para sus diversas necesidades de embeddings.

Desbloqueando un significado más profundo para los datos
Los embeddings son la tecnología que impulsa las experiencias en muchos productos de Google. Desde RAG, donde los embeddings pueden desempeñar un papel crucial en la ingeniería de contexto, hasta la gestión de datos a gran escala y la búsqueda/análisis clásicos, algunos de nuestros socios de acceso temprano ya están usando Gemini Embedding 2 para desbloquear aplicaciones multimodales de alto valor:
*"Elegimos los embeddings de Gemini para ayudar a los profesionales legales a encontrar información crítica durante el proceso de descubrimiento en litigios, un desafío altamente técnico en un entorno de alto riesgo, y uno en el que Gemini sobresale. En nuestras pruebas más recientes, el modelo de embedding multimodal de Gemini mejora la precisión y el recall en millones de registros, mientras desbloquea una potente funcionalidad de búsqueda para imágenes y videos. Para los profesionales legales, estas nuevas capacidades abren formas completamente novedosas de entender rápidamente los materiales del caso, incluso en los asuntos más grandes."
*
**Max Christoff
CTO
Everlaw**
"Gemini Embedding 2 es la base del Motor de Igualdad Económica para Creadores de Sparkonomy. Su multimodalidad nativa reduce nuestra latencia hasta en un 70% al eliminar la inferencia de LLM y casi duplica las puntuaciones de similitud semántica para pares de texto-imagen y texto-video, saltando de 0.4 a 0.8. Esto impulsa nuestro Genoma del Creador propietario para indexar millones de minutos de video, junto con imágenes y texto, con una precisión sin precedentes, desbloqueando colaboraciones de marca imparciales y democratizando el éxito económico para cada creador."
**Guneet Singh
Co-fundador
Sparkonomy**
"La continuidad de la API es excelente. Gemini Embedding 2 se integra directamente en nuestro flujo de trabajo actual con cambios mínimos. Estamos probando nuevas formas de incrustar recuerdos conversacionales basados en texto junto con embeddings de audio y visuales, especialmente pares de preguntas y respuestas de asistentes, y estamos viendo un aumento del 20% en el recall top-1 para nuestra aplicación de bienestar personal."
**Ertuğrul Çavuşoğlu
Co-fundador
Mindlid**
Comienza a construir hoy
Comienza con el modelo Gemini Embedding 2 a través de la API de Gemini o Vertex AI.
1from google import genai2from google.genai import types34# Para Vertex AI:5# PROJECT_ID='<add_here>'6# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')78client = genai.Client()910with open("example.png", "rb") as f:11 image_bytes = f.read()1213with open("sample.mp3", "rb") as f:14 audio_bytes = f.read()1516# Incrustar texto, imagen y audio17result = client.models.embed_content(18 model="gemini-embedding-2-preview",19 contents=[20 "¿Cuál es el sentido de la vida?",21 types.Part.from_bytes(22 data=image_bytes,23 mime_type="image/png",24 ),25 types.Part.from_bytes(26 data=audio_bytes,27 mime_type="audio/mpeg",28 ),29 ],30)3132print(result.embeddings)
Aprende a usar el modelo en nuestros cuadernos interactivos de Colab para la API de Gemini y Vertex AI. También puedes usarlo a través de LangChain, LlamaIndex, Haystack, Weaviate, QDrant, ChromaDB y Vector Search.
Al aportar significado semántico a los diversos datos que nos rodean, Gemini Embedding 2 proporciona la base multimodal esencial para la próxima era de experiencias avanzadas de IA. Estamos ansiosos por ver lo que construirás.





