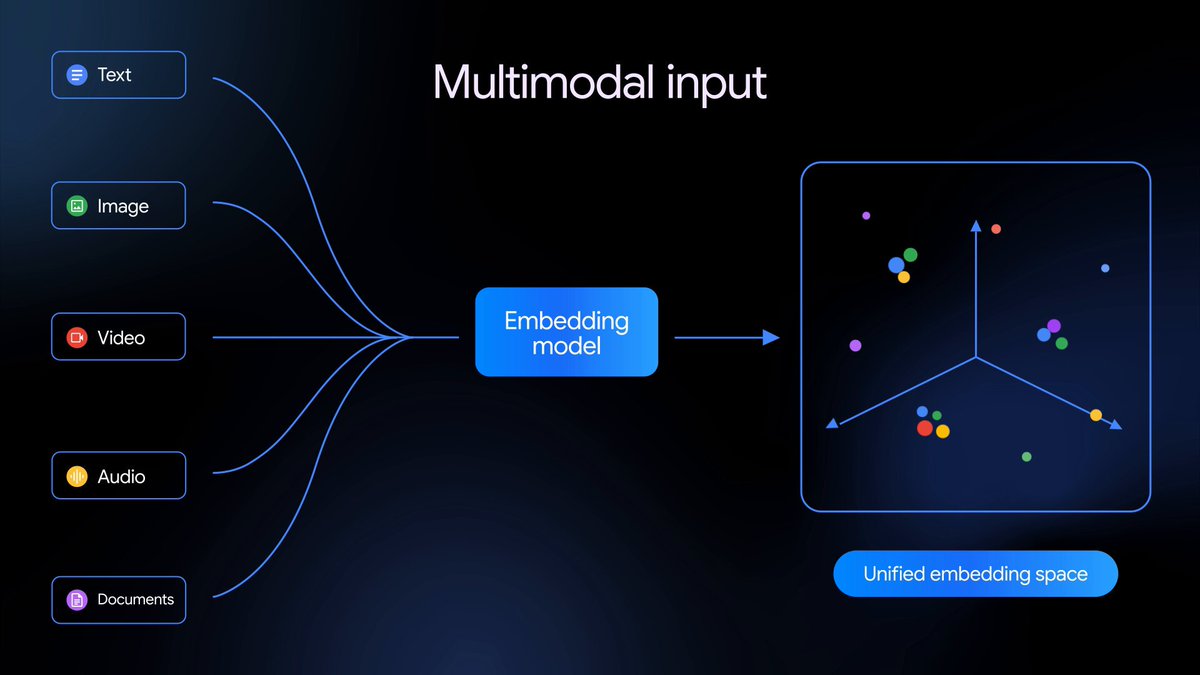
Gemini Embedding 2 è il nostro primo modello di embedding nativamente multimodale che mappa testo, immagini, video, audio e documenti in un unico spazio di embedding, consentendo il recupero e la classificazione multimodale attraverso diversi tipi di media — ed è ora disponibile in anteprima pubblica.
Oggi rilasciamo Gemini Embedding 2, il nostro primo modello di embedding completamente multimodale basato sull'architettura Gemini, in anteprima pubblica tramite Gemini API e Vertex AI.
Basandosi sulla nostra precedente fondazione solo testuale, Gemini Embedding 2 mappa testo, immagini, video, audio e documenti in un unico spazio di embedding unificato e cattura l'intento semantico in oltre 100 lingue. Questo semplifica pipeline complesse e migliora un'ampia varietà di attività downstream multimodali, dal Retrieval-Augmented Generation (RAG) e la ricerca semantica all'analisi del sentiment e al clustering dei dati.
Nuove modalità e dimensioni di output flessibili
Il modello si basa su Gemini e sfrutta le sue capacità di comprensione multimodale di prim'ordine per creare embedding di alta qualità su:
- Testo: supporta un contesto espanso fino a 8192 token di input
- Immagini: in grado di elaborare fino a 6 immagini per richiesta, supportando i formati PNG e JPEG
- Video: supporta fino a 120 secondi di input video nei formati MP4 e MOV
- Audio: acquisisce e incorpora nativamente i dati audio senza bisogno di trascrizioni testuali intermedie
- Documenti: incorpora direttamente PDF fino a 6 pagine
Oltre a elaborare una modalità alla volta, questo modello comprende nativamente input intervallati, così puoi passare più modalità di input (ad esempio, immagine + testo) in una singola richiesta. Ciò consente al modello di catturare le relazioni complesse e sfumate tra diversi tipi di media, sbloccando una comprensione più accurata di dati complessi del mondo reale.
0:37
Come i nostri precedenti modelli di embedding, Gemini Embedding 2 incorpora Matryoshka Representation Learning (MRL), una tecnica che "annida" le informazioni riducendo dinamicamente le dimensioni. Ciò consente dimensioni di output flessibili che si riducono dal valore predefinito di 3072, permettendo agli sviluppatori di bilanciare prestazioni e costi di archiviazione. Raccomandiamo di utilizzare dimensioni 3072, 1536, 768 per la massima qualità.
Prestazioni all'avanguardia
Gemini Embedding 2 non si limita a migliorare i modelli precedenti. Stabilisce un nuovo standard di prestazioni per la profondità multimodale, introducendo forti capacità vocali e superando i modelli leader nei compiti di testo, immagine e video. Questo miglioramento misurabile e la copertura multimodale unica offrono agli sviluppatori esattamente ciò di cui hanno bisogno per le loro diverse esigenze di embedding.

Sbloccare un significato più profondo per i dati
Gli embedding sono la tecnologia che alimenta le esperienze in molti prodotti Google. Dal RAG, dove gli embedding possono svolgere un ruolo cruciale nell'ingegneria del contesto, alla gestione dei dati su larga scala e alla ricerca/analisi classica, alcuni dei nostri partner in accesso anticipato stanno già utilizzando Gemini Embedding 2 per sbloccare applicazioni multimodali di alto valore:
*"Abbiamo scelto gli embedding di Gemini per aiutare i professionisti legali a trovare informazioni critiche durante il processo di discovery nei contenziosi — una sfida altamente tecnica in un contesto ad alto rischio, e una in cui Gemini eccelle. Nei nostri test più recenti, il modello di embedding multimodale di Gemini migliora precisione e richiamo su milioni di record, sbloccando al contempo potenti nuove funzionalità di ricerca per immagini e video. Per i professionisti legali, queste nuove capacità aprono modi completamente nuovi per comprendere rapidamente i materiali del caso, anche nelle questioni più grandi."
*
**Max Christoff
CTO
Everlaw**
"Gemini Embedding 2 è il fondamento del Creator Economic Equality Engine di Sparkonomy. La sua multi-modalità nativa riduce la nostra latenza fino al 70% eliminando l'inferenza LLM e quasi raddoppia i punteggi di similarità semantica per coppie testo-immagine e testo-video, passando da 0,4 a 0,8. Questo alimenta il nostro Creator Genome proprietario per indicizzare milioni di minuti di video, insieme a immagini e testo, con una precisione senza precedenti, sbloccando collaborazioni di marca imparziali e democratizzando il successo economico per ogni creatore."
**Guneet Singh
Co-fondatore
Sparkonomy**
"La continuità dell'API è eccellente. Gemini Embedding 2 si inserisce perfettamente nel nostro flusso di lavoro esistente con modifiche minime. Stiamo testando nuovi modi per incorporare ricordi conversazionali basati su testo insieme a embedding audio e visivi, in particolare coppie di domande e risposte dell'assistente, e stiamo osservando un aumento del 20% nel richiamo top-1 per la nostra app di benessere personale."
**Ertuğrul Çavuşoğlu
Co-fondatore
Mindlid**
Inizia a costruire oggi
Inizia con il modello Gemini Embedding 2 tramite Gemini API o Vertex AI.
1from google import genai2from google.genai import types34# Per Vertex AI:5# PROJECT_ID='<add_here>'6# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')78client = genai.Client()910with open("example.png", "rb") as f:11 image_bytes = f.read()1213with open("sample.mp3", "rb") as f:14 audio_bytes = f.read()1516# Incorpora testo, immagine e audio17result = client.models.embed_content(18 model="gemini-embedding-2-preview",19 contents=[20 "What is the meaning of life?",21 types.Part.from_bytes(22 data=image_bytes,23 mime_type="image/png",24 ),25 types.Part.from_bytes(26 data=audio_bytes,27 mime_type="audio/mpeg",28 ),29 ],30)3132print(result.embeddings)
Scopri come utilizzare il modello nei nostri notebook Colab interattivi di Gemini API e Vertex AI. Puoi anche utilizzarlo tramite LangChain, LlamaIndex, Haystack, Weaviate, QDrant, ChromaDB e Vector Search.
Portando significato semantico ai diversi dati che ci circondano, Gemini Embedding 2 fornisce la base multimodale essenziale per la prossima era di esperienze AI avanzate. Non vediamo l'ora di vedere cosa costruirai.





