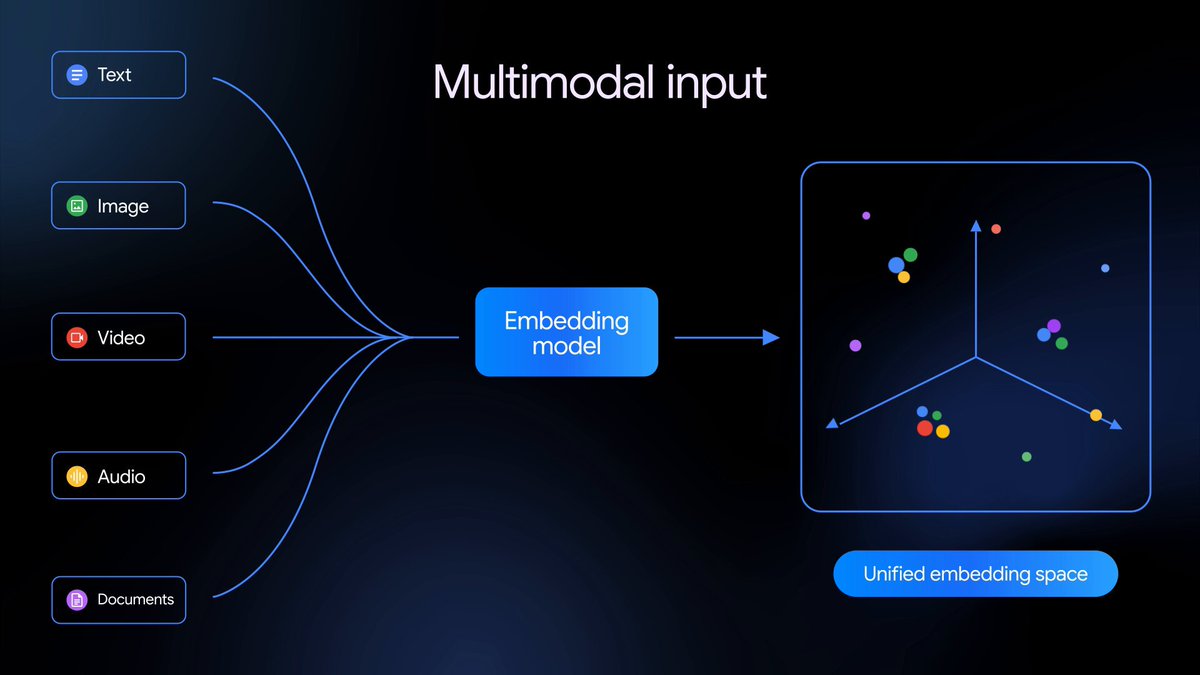
Gemini Embedding 2 는 텍스트, 이미지, 비디오, 오디오 및 문서를 단일 임베딩 공간에 매핑하는 Google 의 첫 번째 네이티브 멀티모달 임베딩 모델로, 다양한 미디어 유형에 걸친 멀티모달 검색 및 분류를 가능하게 합니다. 현재 공개 프리뷰로 제공됩니다.
오늘 저희는 Gemini 아키텍처를 기반으로 구축된 최초의 완전한 멀티모달 임베딩 모델인 Gemini Embedding 2 를 Gemini API 및 Vertex AI를 통해 공개 프리뷰로 출시합니다.
이전의 텍스트 전용 기반을 확장하여, Gemini Embedding 2 는 텍스트, 이미지, 비디오, 오디오 및 문서를 단일 통합 임베딩 공간에 매핑하고 100 개 이상의 언어에 걸친 의미적 의도를 포착합니다. 이는 복잡한 파이프라인을 단순화하고 검색 증강 생성(RAG), 의미 검색부터 감정 분석 및 데이터 클러스터링에 이르기까지 다양한 멀티모달 다운스트림 작업을 향상시킵니다.
새로운 모달리티와 유연한 출력 차원
이 모델은 Gemini 를 기반으로 하며 최고 수준의 멀티모달 이해 기능을 활용하여 다음 분야에서 고품질 임베딩을 생성합니다:
- 텍스트: 최대 8192 개의 입력 토큰을 지원하는 광범위한 컨텍스트 지원
- 이미지: 요청당 최대 6 개의 이미지 처리 가능, PNG 및 JPEG 형식 지원
- 비디오: MP4 및 MOV 형식의 최대 120 초 비디오 입력 지원
- 오디오: 중간 텍스트 변환 없이 오디오 데이터를 네이티브로 수집 및 임베딩
- 문서: 최대 6 페이지 길이의 PDF 를 직접 임베딩
한 번에 하나의 모달리티를 처리하는 것을 넘어, 이 모델은 인터리브된 입력을 네이티브로 이해하므로 단일 요청에서 여러 모달리티(예: 이미지 + 텍스트)를 전달할 수 있습니다. 이를 통해 모델은 다양한 미디어 유형 간의 복잡하고 미묘한 관계를 포착하여 복잡한 실제 데이터에 대한 더 정확한 이해를 가능하게 합니다.
0:37
이전 임베딩 모델과 마찬가지로, Gemini Embedding 2 는 차원을 동적으로 축소하여 정보를 "중첩"하는 기술인 Matryoshka Representation Learning(MRL)을 통합합니다. 이를 통해 기본값 3072 에서 축소되는 유연한 출력 차원을 가능하게 하여 개발자가 성능과 스토리지 비용의 균형을 맞출 수 있습니다. 최고 품질을 위해 3072, 1536, 768 차원을 사용하는 것을 권장합니다.
최첨단 성능
Gemini Embedding 2 는 단순히 레거시 모델을 개선하는 데 그치지 않습니다. 멀티모달 깊이에 대한 새로운 성능 기준을 수립하며, 강력한 음성 기능을 도입하고 텍스트, 이미지 및 비디오 작업에서 선도적인 모델을 능가합니다. 이러한 측정 가능한 개선과 독특한 멀티모달 커버리지는 개발자에게 다양한 임베딩 요구 사항에 필요한 것을 정확히 제공합니다.

데이터의 더 깊은 의미 활용하기
임베딩은 많은 Google 제품에서 경험을 구동하는 기술입니다. 임베딩이 컨텍스트 엔지니어링에서 중요한 역할을 할 수 있는 RAG 부터 대규모 데이터 관리 및 기존 검색/분석에 이르기까지, 일부 얼리 액세스 파트너는 이미 Gemini Embedding 2 를 사용하여 고부가가치 멀티모달 애플리케이션을 활용하고 있습니다:
*"저희는 법률 전문가들이 소송 중 증거 개시 과정에서 중요한 정보를 찾을 수 있도록 Gemini 임베딩을 선택했습니다. 이는 매우 기술적인 도전 과제이며, 높은 이해관계가 걸린 환경에서 Gemini 가 탁월한 성과를 보이는 분야입니다. 최근 테스트에서 Gemini 의 멀티모달 임베딩 모델은 수백만 개의 레코드에 걸쳐 정밀도와 재현율을 향상시키는 동시에 이미지와 비디오에 대한 강력한 새로운 검색 기능을 제공합니다. 법률 전문가들에게 이러한 새로운 기능은 가장 큰 사건에서도 사건 자료를 신속하게 이해할 수 있는 완전히 새로운 방법을 열어줍니다."
*
**Max Christoff
CTO
Everlaw**
"Gemini Embedding 2 는 Sparkonomy 의 크리에이터 경제 평등 엔진의 기반입니다. 네이티브 멀티모달리티는 LLM 추론을 제거하여 지연 시간을 최대 70% 단축하고 텍스트-이미지 및 텍스트-비디오 쌍에 대한 의미 유사도 점수를 0.4 에서 0.8 로 거의 두 배로 높입니다. 이는 독점적인 Creator Genome 이 수백만 분의 비디오를 이미지 및 텍스트와 함께 전례 없는 정밀도로 인덱싱하여 편향되지 않은 브랜드 협업을 가능하게 하고 모든 크리에이터를 위한 경제적 성공을 민주화할 수 있게 해줍니다."
**Guneet Singh
공동 창업자
Sparkonomy**
"API 연속성이 뛰어납니다. Gemini Embedding 2 는 최소한의 변경만으로 기존 워크플로우에 바로 통합됩니다. 저희는 텍스트 기반 대화 기억을 오디오 및 시각적 임베딩, 특히 어시스턴트 질문-답변 쌍과 함께 임베딩하는 새로운 방법을 테스트 중이며, 개인 웰니스 앱에서 상위 1 개 재현율이 20% 향상되는 것을 확인하고 있습니다."
**Ertuğrul Çavuşoğlu
공동 창업자
Mindlid**
지금 바로 구축 시작하기
Gemini API 또는 Vertex AI를 통해 Gemini Embedding 2 모델을 시작해보세요.
1from google import genai2from google.genai import types34# For Vertex AI:5# PROJECT_ID='<add_here>'6# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')78client = genai.Client()910with open("example.png", "rb") as f:11 image_bytes = f.read()1213with open("sample.mp3", "rb") as f:14 audio_bytes = f.read()1516# Embed text, image, and audio17result = client.models.embed_content(18 model="gemini-embedding-2-preview",19 contents=[20 "What is the meaning of life?",21 types.Part.from_bytes(22 data=image_bytes,23 mime_type="image/png",24 ),25 types.Part.from_bytes(26 data=audio_bytes,27 mime_type="audio/mpeg",28 ),29 ],30)3132print(result.embeddings)
대화형 Gemini API 및 Vertex AI Colab 노트북에서 모델 사용 방법을 알아보세요. 또한 LangChain, LlamaIndex, Haystack, Weaviate, QDrant, ChromaDB 및 Vector Search를 통해서도 사용할 수 있습니다.
주변의 다양한 데이터에 의미를 부여함으로써, Gemini Embedding 2 는 차세대 고급 AI 경험을 위한 필수적인 멀티모달 기반을 제공합니다. 여러분이 무엇을 구축하실지 정말 기대됩니다.





