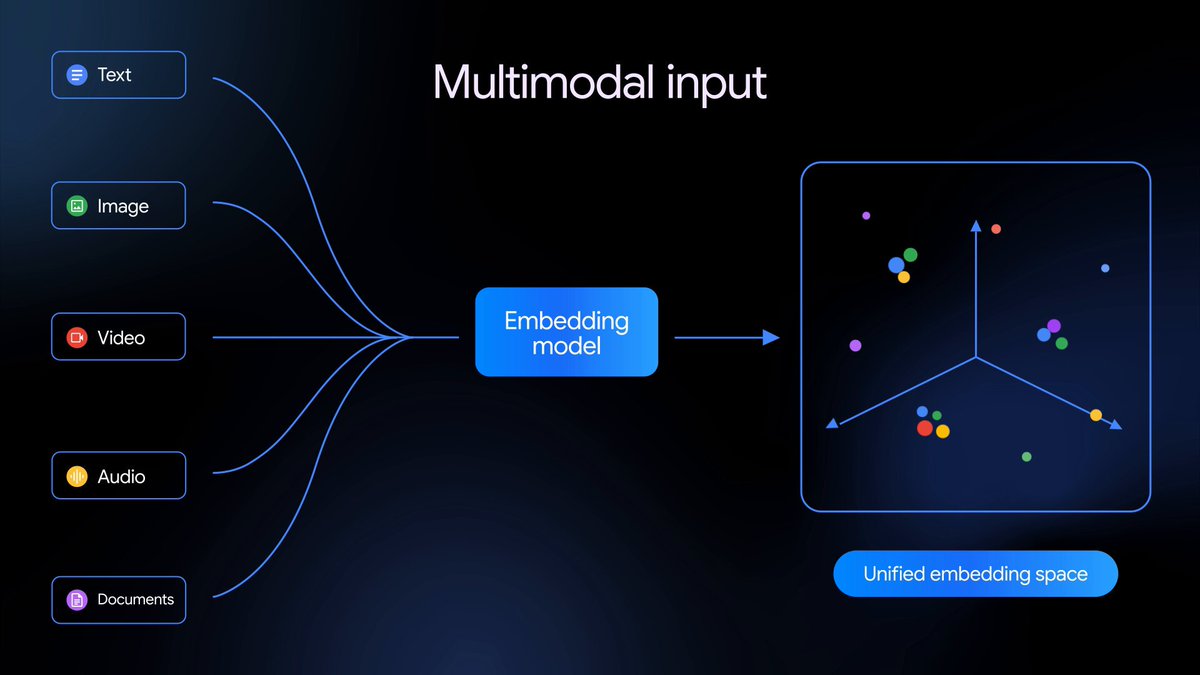
Gemini Embedding 2 เป็นโมเดล embedding แบบ multimodal ดั้งเดิมตัวแรกของเราที่แมปข้อความ รูปภาพ วิดีโอ เสียง และเอกสารเข้าไว้ในพื้นที่ embedding เดียวกัน ทำให้สามารถค้นคืนและจำแนกข้อมูลแบบ multimodal ข้ามสื่อประเภทต่างๆ ได้ — และตอนนี้พร้อมให้ใช้งานในรุ่น public preview แล้ว
วันนี้เรากำลังเปิดตัว Gemini Embedding 2 ซึ่งเป็นโมเดล embedding แบบ multimodal เต็มรูปแบบตัวแรกของเราที่สร้างบนสถาปัตยกรรม Gemini ในรุ่น Public Preview ผ่าน Gemini API และ Vertex AI
ต่อยอดจากพื้นฐานที่รองรับเฉพาะข้อความในรุ่นก่อนหน้า Gemini Embedding 2 แมปข้อความ รูปภาพ วิดีโอ เสียง และเอกสารเข้าไว้ในพื้นที่ embedding ที่เป็นหนึ่งเดียว และจับความหมายเชิงความหมายในกว่า 100 ภาษา ซึ่งช่วยลดความซับซ้อนของ pipeline และปรับปรุงงานปลายทางแบบ multimodal ที่หลากหลาย ตั้งแต่ Retrieval-Augmented Generation (RAG) และการค้นหาเชิงความหมาย ไปจนถึงการวิเคราะห์ความรู้สึกและการจัดกลุ่มข้อมูล
โมดอลใหม่และมิติเอาต์พุตที่ยืดหยุ่น
โมเดลนี้ใช้ Gemini และใช้ประโยชน์จากความสามารถในการทำความเข้าใจแบบ multimodal ระดับดีเยี่ยมเพื่อสร้าง embedding คุณภาพสูงใน:
- ข้อความ: รองรับบริบทที่กว้างขวางสูงสุด 8192 โทเค็นอินพุต
- รูปภาพ: สามารถประมวลผลรูปภาพได้สูงสุด 6 ภาพต่อคำขอ รองรับรูปแบบ PNG และ JPEG
- วิดีโอ: รองรับวิดีโออินพุตสูงสุด 120 วินาทีในรูปแบบ MP4 และ MOV
- เสียง: รับและฝังข้อมูลเสียงโดยตรงโดยไม่ต้องใช้การถอดความข้อความขั้นกลาง
- เอกสาร: ฝัง PDF ได้โดยตรงสูงสุด 6 หน้า
นอกเหนือจากการประมวลผลทีละโมดอลแล้ว โมเดลนี้ยังเข้าใจอินพุตแบบสลับกันโดยธรรมชาติ คุณจึงสามารถส่งอินพุตหลายโมดอล (เช่น รูปภาพ + ข้อความ) ในคำขอเดียวได้ ซึ่งช่วยให้โมเดลจับความสัมพันธ์ที่ซับซ้อนและละเอียดอ่อนระหว่างสื่อประเภทต่างๆ ปลดล็อกความเข้าใจที่แม่นยำยิ่งขึ้นเกี่ยวกับข้อมูลที่ซับซ้อนในโลกจริง
0:37
เช่นเดียวกับโมเดล embedding รุ่นก่อนหน้า Gemini Embedding 2 ใช้ Matryoshka Representation Learning (MRL) ซึ่งเป็นเทคนิคที่ 'ซ้อน' ข้อมูลโดยการลดขนาดมิติแบบไดนามิก ทำให้สามารถปรับขนาดมิติเอาต์พุตได้อย่างยืดหยุ่นจากค่าเริ่มต้น 3072 เพื่อให้นักพัฒนาสามารถปรับสมดุลระหว่างประสิทธิภาพและต้นทุนการจัดเก็บ เราขอแนะนำให้ใช้มิติ 3072, 1536, 768 เพื่อคุณภาพสูงสุด
ประสิทธิภาพระดับแนวหน้า
Gemini Embedding 2 ไม่ได้แค่ปรับปรุงจากโมเดลรุ่นเก่าเท่านั้น แต่ยังสร้างมาตรฐานประสิทธิภาพใหม่สำหรับความลึกแบบ multimodal โดยแนะนำความสามารถด้านเสียงที่แข็งแกร่งและมีประสิทธิภาพเหนือกว่าโมเดลชั้นนำในงานข้อความ รูปภาพ และวิดีโอ การปรับปรุงที่วัดได้และการครอบคลุมแบบ multimodal ที่ไม่เหมือนใครนี้มอบสิ่งที่นักพัฒนาต้องการสำหรับความต้องการ embedding ที่หลากหลาย

ปลดล็อกความหมายที่ลึกซึ้งยิ่งขึ้นสำหรับข้อมูล
Embedding คือเทคโนโลยีที่ขับเคลื่อนประสบการณ์ในผลิตภัณฑ์ Google หลายรายการ ตั้งแต่ RAG ที่ embedding มีบทบาทสำคัญในการปรับแต่งบริบท ไปจนถึงการจัดการข้อมูลขนาดใหญ่และการค้นหา/วิเคราะห์แบบคลาสสิก พันธมิตรที่เข้าถึงก่อนบางรายของเรากำลังใช้ Gemini Embedding 2 เพื่อปลดล็อกแอปพลิเคชัน multimodal ที่มีมูลค่าสูงแล้ว:
*"เราเลือก Gemini embeddings เพื่อช่วยให้ผู้เชี่ยวชาญด้านกฎหมายค้นหาข้อมูลสำคัญในระหว่างกระบวนการค้นหาหลักฐานในการดำเนินคดี ซึ่งเป็นความท้าทายทางเทคนิคสูงในสถานการณ์ที่มีความเสี่ยงสูง และเป็นสิ่งที่ Gemini ทำได้ดีเยี่ยม ในการทดสอบล่าสุดของเรา โมเดล embedding แบบ multimodal ของ Gemini ช่วยเพิ่ม precision และ recall ในหลายล้านเรกคอร์ด พร้อมปลดล็อกฟังก์ชันการค้นหาใหม่ที่ทรงพลังสำหรับรูปภาพและวิดีโอ สำหรับผู้เชี่ยวชาญด้านกฎหมาย ความสามารถใหม่เหล่านี้เปิดวิธีใหม่ทั้งหมดในการทำความเข้าใจเอกสารคดีอย่างรวดเร็ว แม้ในคดีที่ใหญ่ที่สุด"
*
**Max Christoff
CTO
Everlaw**
"Gemini Embedding 2 เป็นรากฐานของ Creator Economic Equality Engine ของ Sparkonomy ความสามารถแบบ multimodal ดั้งเดิมของมันช่วยลด latency ของเราได้ถึง 70% โดยการตัดการอนุมานของ LLM และเพิ่มคะแนนความคล้ายคลึงเชิงความหมายสำหรับคู่ข้อความ-รูปภาพและข้อความ-วิดีโอเกือบสองเท่า—จาก 0.4 เป็น 0.8 ซึ่งขับเคลื่อน Creator Genome ที่เป็นกรรมสิทธิ์ของเราในการจัดทำดัชนีวิดีโอหลายล้านนาที พร้อมรูปภาพและข้อความ ด้วยความแม่นยำที่ไม่เคยมีมาก่อน—ปลดล็อกความร่วมมือกับแบรนด์ที่ปราศจากอคติและทำให้ความสำเร็จทางเศรษฐกิจเป็นประชาธิปไตยสำหรับทุกครีเอเตอร์"
**Guneet Singh
ผู้ร่วมก่อตั้ง
Sparkonomy**
"ความต่อเนื่องของ API นั้นยอดเยี่ยมมาก Gemini Embedding 2 เข้ากับเวิร์กโฟลว์ที่มีอยู่ของเราได้ทันทีโดยมีการเปลี่ยนแปลงน้อยมาก เรากำลังทดสอบวิธีใหม่ในการฝังความทรงจำจากการสนทนาที่เป็นข้อความร่วมกับ embedding เสียงและภาพ โดยเฉพาะคู่คำถาม-คำตอบของผู้ช่วย และเห็นการเพิ่มขึ้น 20% ใน top-1 recall สำหรับแอปพลิเคชันเพื่อสุขภาพส่วนบุคคลของเรา"
**Ertuğrul Çavuşoğlu
ผู้ร่วมก่อตั้ง
Mindlid**
เริ่มสร้างวันนี้
เริ่มต้นใช้งานโมเดล Gemini Embedding 2 ผ่าน Gemini API หรือ Vertex AI
1from google import genai2from google.genai import types34# สำหรับ Vertex AI:5# PROJECT_ID='<add_here>'6# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')78client = genai.Client()910with open("example.png", "rb") as f:11 image_bytes = f.read()1213with open("sample.mp3", "rb") as f:14 audio_bytes = f.read()1516# ฝังข้อความ รูปภาพ และเสียง17result = client.models.embed_content(18 model="gemini-embedding-2-preview",19 contents=[20 "ความหมายของชีวิตคืออะไร?",21 types.Part.from_bytes(22 data=image_bytes,23 mime_type="image/png",24 ),25 types.Part.from_bytes(26 data=audio_bytes,27 mime_type="audio/mpeg",28 ),29 ],30)3132print(result.embeddings)
เรียนรู้วิธีใช้โมเดลใน Colab notebooks แบบโต้ตอบของเรา Gemini API และ Vertex AI คุณยังสามารถใช้ผ่าน LangChain, LlamaIndex, Haystack, Weaviate, QDrant, ChromaDB และ Vector Search
ด้วยการนำความหมายเชิงความหมายมาสู่ข้อมูลที่หลากหลายรอบตัวเรา Gemini Embedding 2 มอบรากฐาน multimodal ที่จำเป็นสำหรับยุคถัดไปของประสบการณ์ AI ขั้นสูง เรารอไม่ไหวที่จะเห็นสิ่งที่คุณสร้าง





