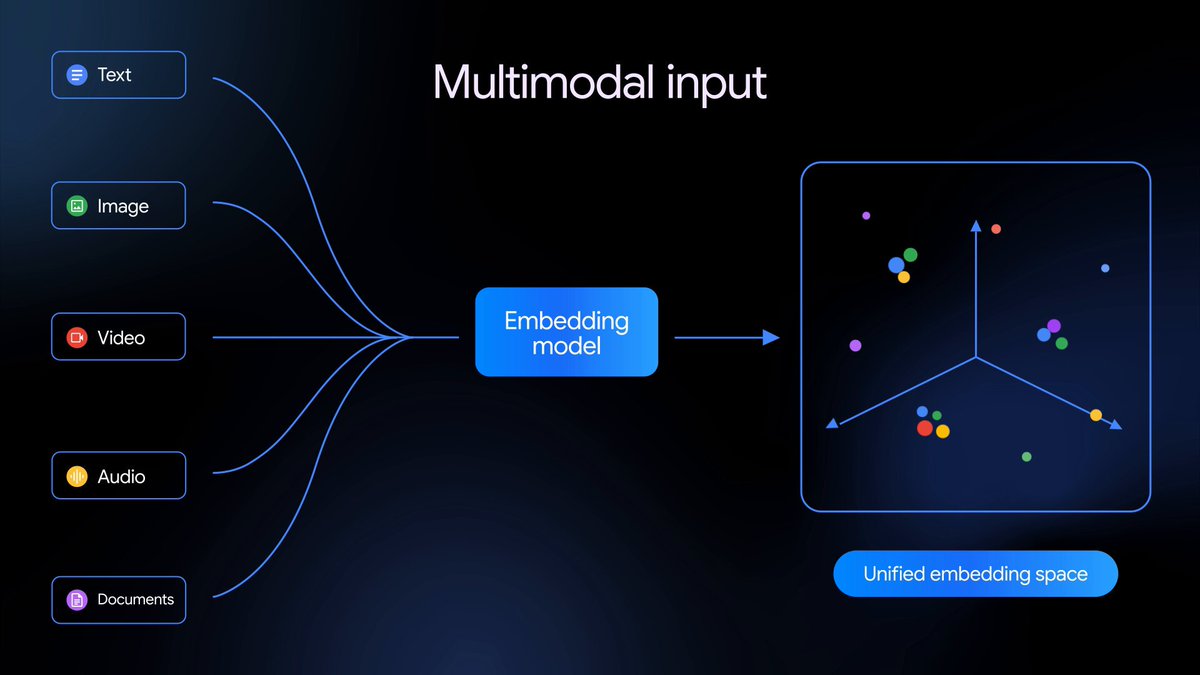
Gemini Embedding 2 は、テキスト、画像、動画、音声、ドキュメントを単一の埋め込み空間にマッピングする、初のネイティブマルチモーダル埋め込みモデルです。これにより、さまざまなメディアタイプにわたるマルチモーダル検索と分類が可能になり、現在パブリックプレビューで利用できます。
本日、Gemini アーキテクチャに基づいて構築された初の完全マルチモーダル埋め込みモデルである Gemini Embedding 2 を、Gemini API および Vertex AI を通じてパブリックプレビューとして公開します。
従来のテキストのみの基盤を拡張し、Gemini Embedding 2 はテキスト、画像、動画、音声、ドキュメントを単一の統合された埋め込み空間にマッピングし、100 以上の言語にわたって意味的な意図を捉えます。これにより、複雑なパイプラインが簡素化され、検索拡張生成(RAG)やセマンティック検索から感情分析、データクラスタリングに至るまで、さまざまなマルチモーダルダウンストリームタスクが強化されます。
新しいモダリティと柔軟な出力次元
このモデルは Gemini をベースにしており、その最高クラスのマルチモーダル理解能力を活用して、以下の分野で高品質な埋め込みを生成します。
- テキスト: 最大 8192 入力トークンという広範なコンテキストをサポート
- 画像: リクエストあたり最大 6 枚の画像を処理可能、PNG および JPEG 形式に対応
- 動画: MP4 および MOV 形式で最大 120 秒の動画入力をサポート
- 音声: 中間テキスト文字起こしを必要とせず、音声データをネイティブに取り込んで埋め込み
- ドキュメント: 最大 6 ページの PDF を直接埋め込み
一度に 1 つのモダリティを処理するだけでなく、このモデルはインターリーブ入力をネイティブに理解するため、1 つのリクエストで複数のモダリティ(例:画像 + テキスト)を渡すことができます。これにより、モデルは異なるメディアタイプ間の複雑で微妙な関係を捉え、複雑な実世界データのより正確な理解を可能にします。
0:37
以前の埋め込みモデルと同様に、Gemini Embedding 2 は Matryoshka Representation Learning(MRL)を採用しています。これは、次元を動的にスケールダウンすることで情報を「入れ子」にする手法です。これにより、デフォルトの 3072 からスケールダウンする柔軟な出力次元が可能になり、開発者はパフォーマンスとストレージコストのバランスを取ることができます。最高品質を得るには、3072、1536、768 の次元を使用することをお勧めします。
最先端のパフォーマンス
Gemini Embedding 2 は、従来のモデルを単に改良するだけではありません。マルチモーダルの深さにおいて新たなパフォーマンス基準を確立し、強力な音声機能を導入し、テキスト、画像、動画タスクで主要モデルを凌駕しています。この測定可能な改善と独自のマルチモーダルカバレッジにより、開発者は多様な埋め込みニーズに正確に応えることができます。

データのより深い意味を引き出す
埋め込みは、多くの Google 製品のエクスペリエンスを支えるテクノロジーです。埋め込みがコンテキストエンジニアリングで重要な役割を果たす RAG から、大規模データ管理、従来の検索/分析に至るまで、一部の早期アクセスパートナーはすでに Gemini Embedding 2 を使用して、価値の高いマルチモーダルアプリケーションを実現しています。
*「私たちは、訴訟におけるディスカバリー(証拠開示)プロセスで法律専門家が重要な情報を見つけるのを支援するために、Gemini 埋め込みを選択しました。これは、ハイステークスな環境での高度に技術的な課題であり、Gemini が得意とする分野です。最新のテストでは、Gemini のマルチモーダル埋め込みモデルにより、数百万件のレコードにわたって精度と再現率が向上し、画像や動画の強力な新しい検索機能が実現されました。法律専門家にとって、これらの新機能は、大規模な案件でもケース資料を迅速に理解するためのまったく新しい方法を開きます。」
*
**Max Christoff
CTO
Everlaw**
「Gemini Embedding 2 は、Sparkonomy の Creator Economic Equality Engine の基盤です。そのネイティブマルチモダリティにより、LLM 推論を排除することでレイテンシを最大 70% 削減し、テキスト-画像およびテキスト-動画ペアのセマンティック類似度スコアを 0.4 から 0.8 へとほぼ倍増させます。これにより、独自の Creator Genome が、画像やテキストとともに数百万分の動画を前例のない精度でインデックス化し、偏りのないブランドコラボレーションを実現し、すべてのクリエイターに経済的成功の民主化をもたらします。」
**Guneet Singh
Co-founder
Sparkonomy**
「API の継続性は優れています。Gemini Embedding 2 は最小限の変更で既存のワークフローにそのまま組み込めます。私たちは、テキストベースの会話メモリを音声および視覚的埋め込みと一緒に埋め込む新しい方法、特にアシスタントの質問と回答のペアをテストしており、パーソナルウェルネスアプリでトップ 1 再現率が 20% 向上しています。」
**Ertuğrul Çavuşoğlu
Co-founder
Mindlid**
今すぐ構築を始める
Gemini Embedding 2 モデルの使用を開始するには、Gemini API または Vertex AI をご利用ください。
1from google import genai2from google.genai import types34# For Vertex AI:5# PROJECT_ID='<add_here>'6# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')78client = genai.Client()910with open("example.png", "rb") as f:11 image_bytes = f.read()1213with open("sample.mp3", "rb") as f:14 audio_bytes = f.read()1516# Embed text, image, and audio17result = client.models.embed_content(18 model="gemini-embedding-2-preview",19 contents=[20 "What is the meaning of life?",21 types.Part.from_bytes(22 data=image_bytes,23 mime_type="image/png",24 ),25 types.Part.from_bytes(26 data=audio_bytes,27 mime_type="audio/mpeg",28 ),29 ],30)3132print(result.embeddings)
インタラクティブな Gemini API および Vertex AI Colab ノートブックでモデルの使用方法を学べます。また、LangChain、LlamaIndex、Haystack、Weaviate、QDrant、ChromaDB、Vector Search を通じて使用することもできます。
私たちの周りの多様なデータに意味的な意味をもたらすことで、Gemini Embedding 2 は、次世代の高度な AI エクスペリエンスに不可欠なマルチモーダル基盤を提供します。皆さんが何を構築するのか、楽しみにしています。





