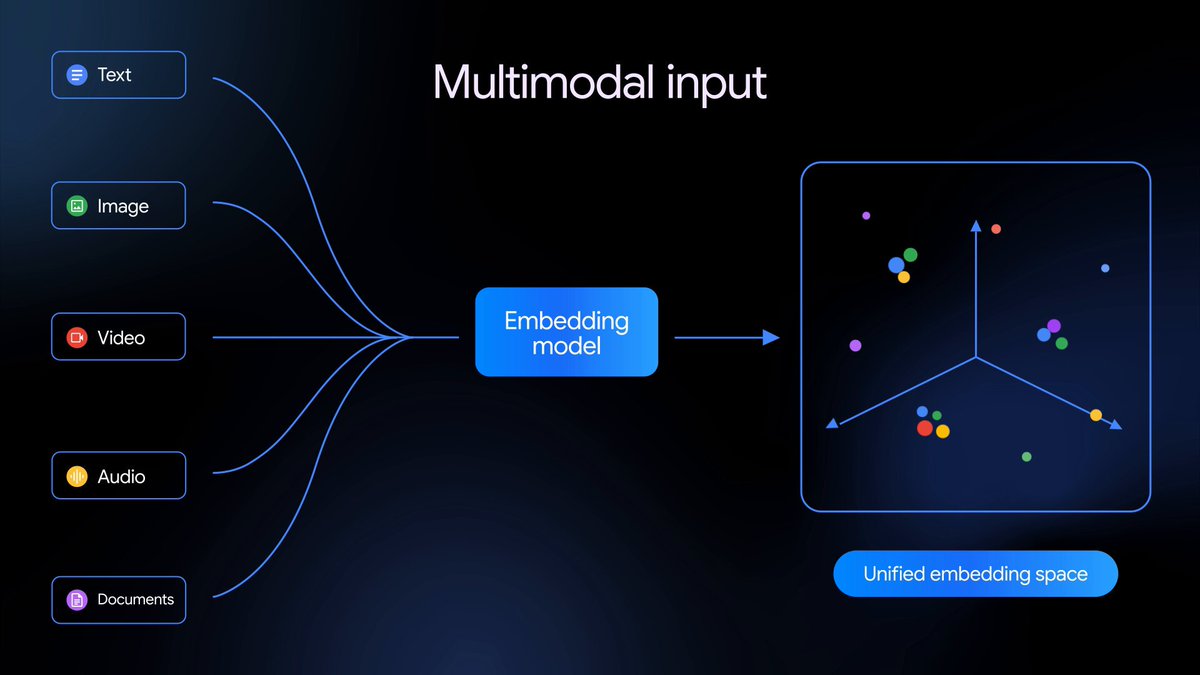
O Gemini Embedding 2 é nosso primeiro modelo de embedding nativamente multimodal que mapeia texto, imagens, vídeo, áudio e documentos em um único espaço de embedding, permitindo recuperação e classificação multimodal em diferentes tipos de mídia — e já está disponível em pré-visualização pública.
Hoje estamos lançando o Gemini Embedding 2, nosso primeiro modelo de embedding totalmente multimodal construído sobre a arquitetura Gemini, em Pré-visualização Pública via Gemini API e Vertex AI.
Expandindo nossa base anterior apenas de texto, o Gemini Embedding 2 mapeia texto, imagens, vídeos, áudio e documentos em um único espaço de embedding unificado, e captura a intenção semântica em mais de 100 idiomas. Isso simplifica pipelines complexos e aprimora uma ampla variedade de tarefas multimodais downstream — desde Geração Aumentada por Recuperação (RAG) e busca semântica até análise de sentimentos e agrupamento de dados.
Novas modalidades e dimensões de saída flexíveis
O modelo é baseado no Gemini e aproveita suas capacidades de compreensão multimodal de ponta para criar embeddings de alta qualidade em:
- Texto: suporta um contexto extenso de até 8192 tokens de entrada
- Imagens: capaz de processar até 6 imagens por requisição, suportando formatos PNG e JPEG
- Vídeos: suporta até 120 segundos de entrada de vídeo nos formatos MP4 e MOV
- Áudio: ingere e incorpora dados de áudio nativamente, sem necessidade de transcrições de texto intermediárias
- Documentos: incorpora PDFs diretamente com até 6 páginas
Além de processar uma modalidade por vez, este modelo entende nativamente entrada intercalada, permitindo que você passe múltiplas modalidades de entrada (ex.: imagem + texto) em uma única requisição. Isso permite que o modelo capture as relações complexas e sutis entre diferentes tipos de mídia, desbloqueando uma compreensão mais precisa de dados complexos do mundo real.
0:37
Assim como nossos modelos de embedding anteriores, o Gemini Embedding 2 incorpora o Aprendizado de Representação Matryoshka (MRL), uma técnica que "aninha" informações ao reduzir dinamicamente as dimensões. Isso permite dimensões de saída flexíveis, reduzindo do padrão de 3072 para que desenvolvedores possam equilibrar desempenho e custos de armazenamento. Recomendamos usar dimensões de 3072, 1536, 768 para a mais alta qualidade.
Desempenho de ponta
O Gemini Embedding 2 não apenas melhora modelos legados. Ele estabelece um novo padrão de desempenho para profundidade multimodal, introduzindo fortes capacidades de fala e superando modelos líderes em tarefas de texto, imagem e vídeo. Essa melhoria mensurável e cobertura multimodal única dão aos desenvolvedores exatamente o que precisam para suas diversas necessidades de embedding.

Desbloqueando significado mais profundo para dados
Embeddings são a tecnologia que impulsiona experiências em muitos produtos do Google. Desde RAG, onde embeddings podem desempenhar um papel crucial na engenharia de contexto, até gerenciamento de dados em larga escala e busca/análise clássica, alguns de nossos parceiros de acesso antecipado já estão usando o Gemini Embedding 2 para desbloquear aplicações multimodais de alto valor:
"Escolhemos os embeddings do Gemini para ajudar profissionais jurídicos a encontrar informações críticas durante o processo de descoberta em litígios — um desafio altamente técnico em um ambiente de alto risco, e no qual o Gemini se destaca. Em nossos testes mais recentes, o modelo de embedding multimodal do Gemini melhora a precisão e o recall em milhões de registros, enquanto desbloqueia novas funcionalidades de busca poderosas para imagens e vídeos. Para profissionais jurídicos, essas novas capacidades abrem maneiras totalmente inovadoras de entender rapidamente os materiais do caso, mesmo nos maiores processos."
Max Christoff
CTO
Everlaw**
"O Gemini Embedding 2 é a base do Motor de Igualdade Econômica para Criadores da Sparkonomy. Sua multimodalidade nativa reduz nossa latência em até 70% ao eliminar a inferência de LLM e quase dobra as pontuações de similaridade semântica para pares texto-imagem e texto-vídeo — saltando de 0,4 para 0,8. Isso alimenta nosso Genoma do Criador proprietário para indexar milhões de minutos de vídeo, junto com imagens e texto, com precisão sem precedentes — desbloqueando colaborações de marca imparciais e democratizando o sucesso econômico para todo criador."
Guneet Singh
Co-fundador
Sparkonomy**
"A continuidade da API é excelente. O Gemini Embedding 2 se encaixa perfeitamente em nosso fluxo de trabalho existente com mudanças mínimas. Estamos testando novas maneiras de incorporar memórias conversacionais baseadas em texto junto com embeddings de áudio e visuais, especialmente pares de perguntas e respostas de assistentes, e vendo um aumento de 20% no recall top-1 para nosso aplicativo de bem-estar pessoal."
Ertuğrul Çavuşoğlu
Co-fundador
Mindlid**
Comece a construir hoje
Comece com o modelo Gemini Embedding 2 através do Gemini API ou Vertex AI.
1from google import genai2from google.genai import types34# Para Vertex AI:5# PROJECT_ID='<add_here>'6# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')78client = genai.Client()910with open("example.png", "rb") as f:11 image_bytes = f.read()1213with open("sample.mp3", "rb") as f:14 audio_bytes = f.read()1516# Incorporar texto, imagem e áudio17result = client.models.embed_content(18 model="gemini-embedding-2-preview",19 contents=[20 "What is the meaning of life?",21 types.Part.from_bytes(22 data=image_bytes,23 mime_type="image/png",24 ),25 types.Part.from_bytes(26 data=audio_bytes,27 mime_type="audio/mpeg",28 ),29 ],30)3132print(result.embeddings)
Aprenda a usar o modelo em nossos notebooks interativos do Colab para Gemini API e Vertex AI. Você também pode usá-lo através de LangChain, LlamaIndex, Haystack, Weaviate, QDrant, ChromaDB e Vector Search.
Ao trazer significado semântico para os diversos dados ao nosso redor, o Gemini Embedding 2 fornece a base multimodal essencial para a próxima era de experiências avançadas de IA. Mal podemos esperar para ver o que você vai construir.





