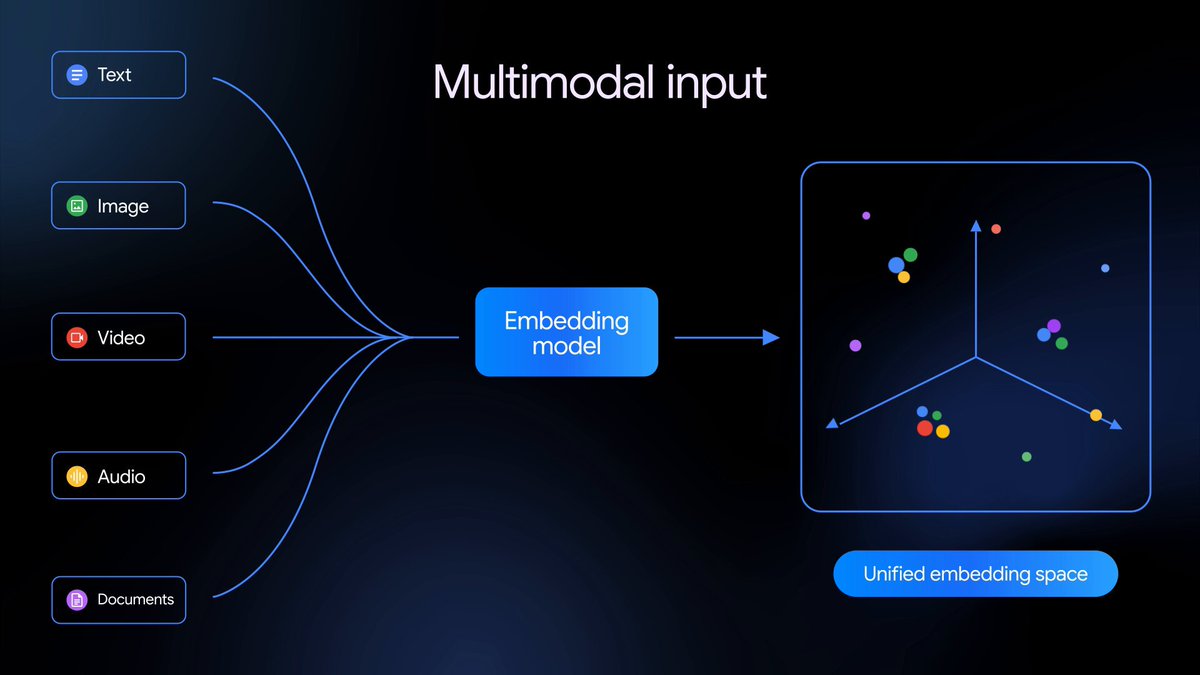
Gemini Embedding 2 是我們首款原生多模態嵌入模型,能將文字、圖片、影片、音訊和文件映射到單一嵌入空間,實現跨不同媒體類型的多模態檢索與分類——目前已於公開預覽版中提供。
今天我們正式推出 Gemini Embedding 2,這是我們基於 Gemini 架構打造的首款完整多模態嵌入模型,已透過 Gemini API 和 Vertex AI 提供公開預覽版。
相較於我們先前僅支援文字的基礎模型,Gemini Embedding 2 能將文字、圖片、影片、音訊和文件映射到單一統一的嵌入空間,並捕捉超過 100 種語言的語義意圖。這簡化了複雜的處理流程,並強化了多種多模態下游任務——從檢索增強生成(RAG)和語義搜尋,到情感分析和資料聚類。
全新模態與靈活的輸出維度
此模型基於 Gemini,並運用其頂尖的多模態理解能力,在以下領域建立高品質嵌入:
- 文字: 支援高達 8192 個輸入 token 的廣闊上下文
- 圖片: 每次請求最多可處理 6 張圖片,支援 PNG 和 JPEG 格式
- 影片: 支援最長 120 秒的影片輸入,格式為 MP4 和 MOV
- 音訊: 原生攝入並嵌入音訊資料,無需中間文字轉錄
- 文件: 直接嵌入最長 6 頁的 PDF
除了每次處理單一模態外,此模型原生理解交錯輸入,因此您可以在單一請求中傳遞多種模態的輸入(例如圖片 + 文字)。這讓模型能夠捕捉不同媒體類型之間複雜細微的關係,從而更準確地理解真實世界的複雜資料。
0:37
與我們先前的嵌入模型一樣,Gemini Embedding 2 採用了 Matryoshka Representation Learning(MRL)技術,這是一種透過動態縮小維度來「嵌套」資訊的技術。這使得輸出維度能夠從預設的 3072 靈活縮小,讓開發者可以在效能與儲存成本之間取得平衡。我們建議使用 3072、1536、768 維度以獲得最高品質。
最先進的效能
Gemini Embedding 2 不僅僅是對舊模型的改進。它為多模態深度建立了新的效能標準,引入了強大的語音能力,並在文字、圖片和影片任務上超越領先模型。這種可衡量的改進和獨特的多模態覆蓋範圍,為開發者提供了滿足其多樣化嵌入需求所需的一切。

為資料解鎖更深層的意義
嵌入技術是許多 Google 產品體驗的基礎。從 RAG(嵌入在情境工程中扮演關鍵角色)到大規模資料管理以及經典的搜尋/分析,我們的一些早期存取合作夥伴已經在使用 Gemini Embedding 2 來解鎖高價值的多模態應用:
*「我們選擇 Gemini 嵌入來幫助法律專業人員在訴訟的發現過程中找到關鍵資訊——這是一項高風險環境中的高度技術挑戰,而 Gemini 在此領域表現出色。在我們最新的測試中,Gemini 的多模態嵌入模型在數百萬筆記錄中提升了精確度與召回率,同時為圖片和影片解鎖了強大的新搜尋功能。對法律專業人員來說,這些新能力開啟了全新的方式,讓他們即使在最龐大的案件中也能快速理解案件材料。」
*
**Max Christoff
技術長
Everlaw**
「Gemini Embedding 2 是 Sparkonomy 創作者經濟平等引擎的基礎。其原生多模態能力將我們的延遲降低了高達 70%(透過移除 LLM 推論),並將文字-圖片和文字-影片對的語義相似度分數從 0.4 躍升至 0.8。這驅動了我們專有的 Creator Genome,以前所未有的精確度索引數百萬分鐘的影片,以及圖片和文字——為每位創作者解鎖無偏見的品牌合作,並讓經濟成功普及化。」
**Guneet Singh
共同創辦人
Sparkonomy**
「API 的連續性非常出色。Gemini Embedding 2 幾乎無需修改就能直接融入我們現有的工作流程。我們正在測試新的方式,將基於文字的對話記憶與音訊和視覺嵌入結合,特別是助理問答對,並在我們的個人健康應用程式中看到了 top-1 召回率提升 20%。」
**Ertuğrul Çavuşoğlu
共同創辦人
Mindlid**
立即開始建構
透過 Gemini API 或 Vertex AI 開始使用 Gemini Embedding 2 模型。
1from google import genai2from google.genai import types34# For Vertex AI:5# PROJECT_ID='<add_here>'6# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')78client = genai.Client()910with open("example.png", "rb") as f:11 image_bytes = f.read()1213with open("sample.mp3", "rb") as f:14 audio_bytes = f.read()1516# Embed text, image, and audio17result = client.models.embed_content(18 model="gemini-embedding-2-preview",19 contents=[20 "What is the meaning of life?",21 types.Part.from_bytes(22 data=image_bytes,23 mime_type="image/png",24 ),25 types.Part.from_bytes(26 data=audio_bytes,27 mime_type="audio/mpeg",28 ),29 ],30)3132print(result.embeddings)
了解如何在我們的互動式 Gemini API 和 Vertex AI Colab 筆記本中使用此模型。您也可以透過 LangChain、LlamaIndex、Haystack、Weaviate、QDrant、ChromaDB 和 Vector Search 來使用它。
透過為我們周圍多樣化的資料帶來語義意義,Gemini Embedding 2 為下一代先進 AI 體驗提供了必要的多模態基礎。我們迫不及待想看到您將建構出什麼。





